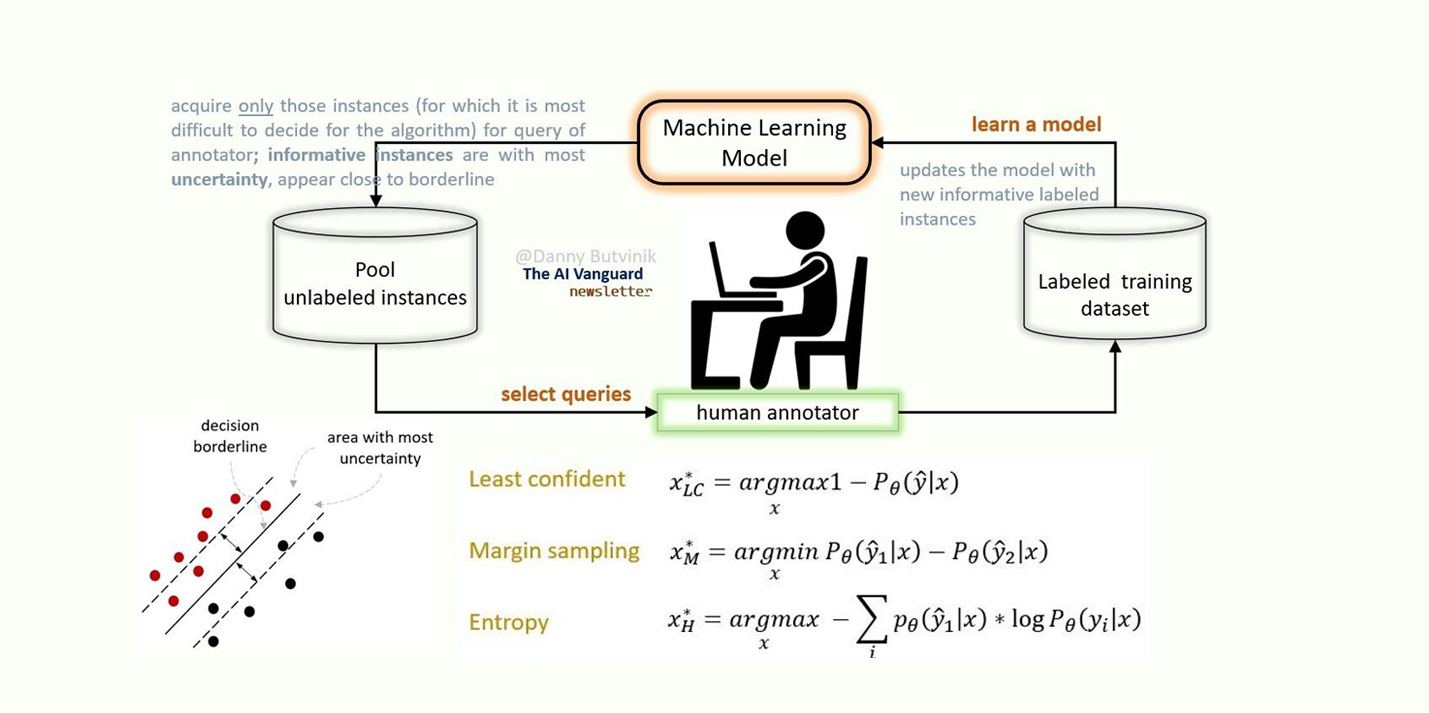
Active machine learning is a type of machine learning where the model can interactively query a human or other intelligent system to obtain more information and improve its accuracy. In this approach, the machine learning model is not just a passive data recipient but an active participant in the learning process.
In statistics literature, it is sometimes also called Optimal Experimental Design (OED)
In traditional machine learning approaches, the model is trained on a fixed set of labeled data and then used to predict new, unseen data. However, in active machine learning, the model can actively choose which data to acquire next based on its current level of uncertainty or lack of knowledge. The model can achieve better accuracy with fewer data points by actively selecting the most informative data points.
There are several approaches to active machine learning, each with advantages and disadvantages. Some common techniques include uncertainty sampling, query-by-committee sampling, pool-based sampling, and diversity sampling.
Uncertainty Sampling involves selecting the data points for which the model is most uncertain or has the highest level of entropy. This approach assumes that the model is least certain about the most informative data points.
Query-by-Committee involves training multiple models on the same data and selecting the data points the models disagree on. This approach assumes that the most informative data points are difficult for the models to agree on.
Pool-based Sampling involves selecting data points from a large pool of unlabeled data to maximize the model’s accuracy on the final labeled data set.
Diversity sampling involves selecting data points dissimilar to those already in the training set. This approach assumes that the most informative data points differ from what the model has already seen.
Active machine learning has many applications, including natural language processing, image and speech recognition, and autonomous driving. It can potentially improve the accuracy and efficiency of machine learning models while reducing the amount of labeled data needed to achieve a given level of accuracy. However, it also requires careful design and evaluation to ensure the model makes informed and meaningful decisions about which data to acquire.